
英文论文评分系统调研报告
部分内容已略去,待项目完结补充之。
背景
中国科大研究生的“科技论文写作”课程要求提交一篇英文学术论文,为提高审核效率,尝试开发一款英文学术论文机器评分系统。
问题定义
输入
理想输入
现存的文本评分系统的输入往往都是纯文本(plain text),只包含无格式的文字信息;而学术论文可被归类为富文本(rich text),包含了样式、图表等信息,为了提高准确性,我们给论文评分系统的输入应尽可能保留原始论文的复杂结构信息。
我们约定:
- 一个
<document>由<title>、<abstract>、<body>、<reference>、<appendix>组成。 <body>和<appendix>由若干<section>组成,<section>亦可包含若干<subsection>。<section>和<subsection>中包含纯文本、<table>、<figure>、<equation>。<reference>由若干<reference-item>构成,<reference-item>包含纯文本。
如上规则的形式化定义:
<document> → <title> <abstract> <body> <reference> <appendix>
<body> → <body> <section>
<appendix> → <appendix> <section>
<section> → <section> <subsection>|<flatten-rich-text>
<subsection> → <subsection> <flatten-rich-text>
<flatten-rich-text> → <plain-text>|<table>|<figure>|<equation>
<reference> → <reference> <reference-item>
<reference-item> → <plain-text>
考虑到机器识别并理解图片、表格、公式的难度,我们将它们栅格化并直接存成图片,对其内容暂不考虑。
根据以上规则,我们尝试借助 XML 语言 表达一篇学术论文:
<document>
<title>Attention Is All You Need</title>
<abstract>The dominant sequence transduction models ... </abstract>
<body>
<section title="Introduction">
Recurrent neural networks, long short-term memory ...
</section>
<section title="Background">
The goal of reducing sequential computation ...
</section>
<section title="Model Architecture">
Most competitive neural sequence transduction ...
<figure
src="./figure/01.png"
caption="The Transformer-model architecture"
/>
<subsection title="Encoder and Decoder Stacks">
Encoder: The encoder is composed of ...
<table src="./table/03.png" caption="Maximum path lengths" />
<equation src="./equation/02.png"/>
</subsection>
</section>
</body>
<reference>
<reference-item>
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer
normalization. arXiv preprint arXiv:1607.06450, 2016.
</reference-item>
<reference-item
>Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine
translation by jointly learning to align and translate. CoRR,
abs/1409.0473, 2014.
</reference-item>
</reference>
<appendix> ... </appendix>
</document>
如上这样的 XML 文件和若干图片,便是我们给机器评分系统的理想输入。
实际输入:源文件 or 导出文件?
显然,我们不可能直接期望用户上传前面所述的“理想输入”,所以我们必须对用户的输入做预处理,使其尽可能接近我们的理想输入。
于是,我们面临期望的输入是源文件还是导出文件的问题。源文件是指论文的 Word 或 LaTeX 源文件,导出文件是指源文件经导出、编译或扫描获得的 PDF 文件。
接下来,我们从“是否易于解析内容”和“是否易于导出”这两个角度来对比分析不同类型的输入。
是否易于解析内容(重要)
“是否易于解析内容”也即是否容易将论文处理成前面的“理想输入”的形式,使用源文件在这方面有巨大的优势。以 LaTeX 为例,通过解析 TeX 文件,利用各类标签(如 section、subsection、 includegraphics、equation),能精确得到论文的文字(包括段落结构)、图片、公式等信息;对于 Word 文件,亦有开源的解析文件内容的第三方工具(例如 python-docx)。与之相比,若使用 PDF 文件则在这方面会遇到不少困难,简单列举如下:
-
如果 PDF 文件是扫描版的,文本不可直接复制,需要先对 PDF 做 OCR 操作,这里可能碰到计算量和精确度的问题。
-
由于自动换行(Word Wrap)机制,使得复制出来的文本有换行但实际应该去除换行。
-
由于断字(Hyphenation)机制,使得一个单词被连字符(hyphen)拆分到行尾和下一行首。
-
段落结构问题。如何识别大小标题(
section、subsection…) 、新段落(例如下图红色剪头指示的新段落)。
-
段落顺序问题。对于多栏文本,除了要遵循先上后下的顺序,还要遵循先左后右的顺序,且先上后下应优先于先左后右。
-
文本归属问题,一段文本到底是属于正文内容还是某个图表的 caption,例如下图中红色框中的文字。
当然以上一些问题解决起来不难,简单写个规则即可,列举出来只是为了说明问题变得“脏”起来。
是否易于导出(不重要)
当用户提交的文件是源文件形式的时候,我们可能还有将其导出为 PDF 的需求(例如为了用于人工审阅、用于归档)。当源文件是 Word 形式的时候,问题还比较好处理,一般就是 Microsoft Office 不同版本兼容性、WPS Office 和 Microsoft Office 兼容性问题导致的显示差异;而当源文件是 LaTeX 文件,我们要为用户在服务端编译时,问题就比较棘手了……
但这个问题不重要,首先,我们的机器评分系统只需要源文件即可不再需要导出的 PDF 了,其次,我们大不了让用户除了上传源文件,还要再提交一份导出的 PDF 文件 :)
小结
总结获得下表:
| 类型 | 详细类型 | 易于解析内容(重要) | 易于导出(不重要) | 综合评分 |
|---|---|---|---|---|
| 源文件 | Word 文件 | ★★★★★ | ★★★☆☆ | ★★★★★ |
| LaTeX 文件 | ★★★★★ | ★☆☆☆☆ | ★★★★☆ | |
| 导出文件 | 可复制的 PDF | ★★★☆☆ | (不需要) | ★★★☆☆ |
| 栅格化的 PDF | ★★☆☆☆ | (不需要) | ★★☆☆☆ | |
| 扫描版 PDF | ★☆☆☆☆ | (不需要) | ★☆☆☆☆ |
整体来说,我们期望用户能上传源文件,最好能再附上论文的 PDF 文件。
当然,如果因为各种原因无法获得论文的源文件、不得不使用 PDF 文件,亦有一些差强人意的解决方案。
例如,如果 PDF 文件是由 Word 或 LaTeX 直接导出的文件,则可使用 PDF 解析工具(例如 pdfminer.six)在 PDF 文件结构上分析论文结构。
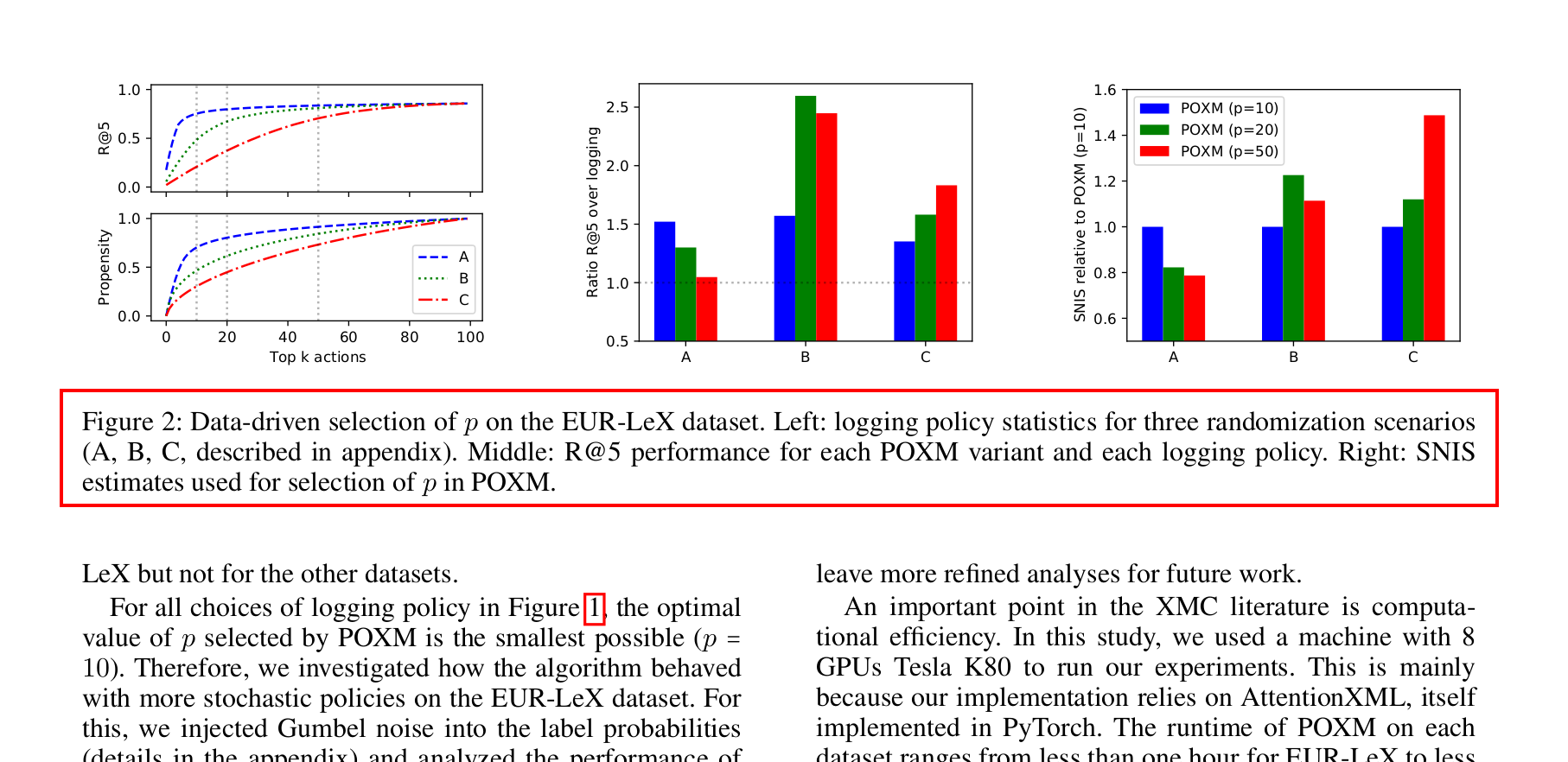
如果只有栅格化或扫描的 PDF 文件,亦有直接分析论文页面图片的兜底策略:OCR + layout parser。说来很巧,为了重排论文用于在 Kindle 上阅读,本人曾封装过一个小工具 reflower,它的运行过程就包含了对论文做文字识别和结构解析的操作。下图是用它对一篇论文做了结构解析后的效果(请转头查看😊;每个框的左上角是元素类型和置信度)。
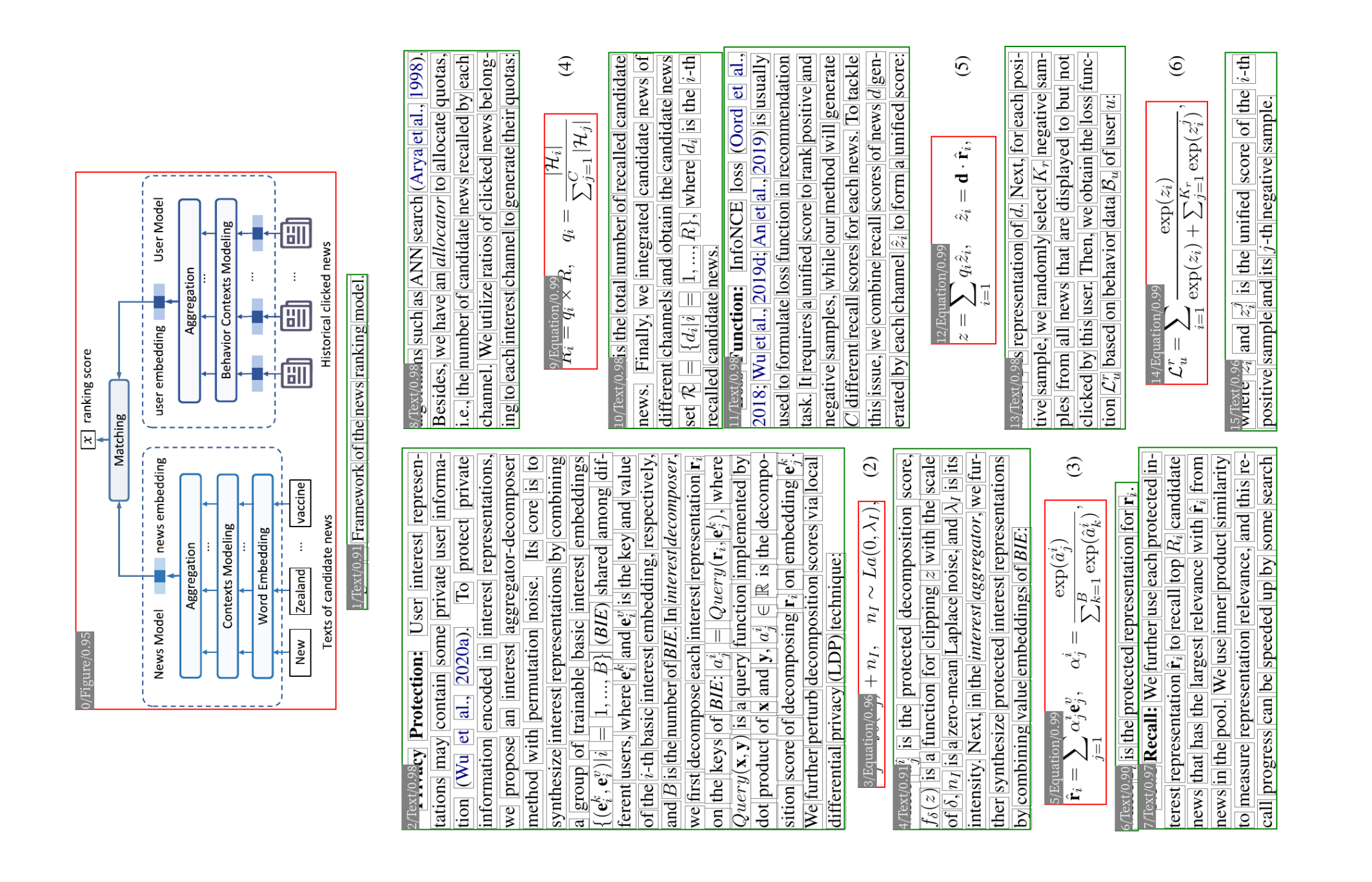
有了这种兜底策略,就算没有源文件,我们也能获得一个接近“理想输入”的结果。于是,本调研报告接下来的关注点将正式放在针对“理想输入”做评分上。
输出
考虑到可解释性的要求和论文评估的多维性,我们为论文输出在各个维度上的评分(每项分数的范围是 0~100),以及将各维评分加权后的综合评分(每项的权重由使用者自行调整)。
现有方案分析
商业闭源产品
在知乎等平台以“语法检查”“润色”等关键词搜索,搜索到几个相对比较知名的产品:Grammarly、QuillBot、批改网(本科上某个老师的英语课,我们的写作作业就是上传到这个平台来打分)。下面我们对这几款产品试用(如果有免费版的话)、分析。
Grammarly
正如其名所示,Grammarly 相对侧重于拼写、语法纠错,这作为基本功能可免费试用,一些更高级的涉及到改写的功能属于会员功能,本人没有会员,因此暂未体验到 :)
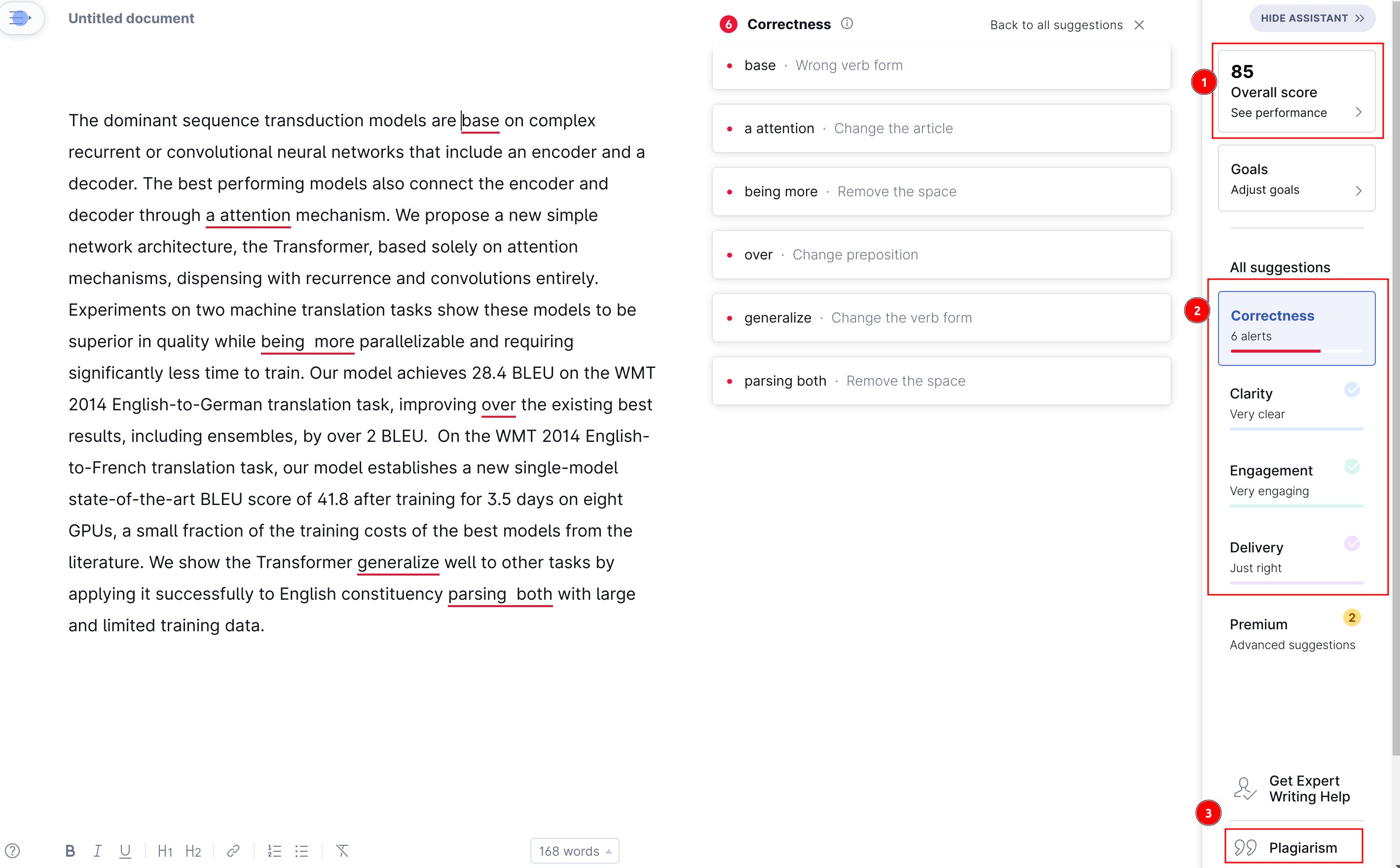
如图中的 ① 所示,Grammarly 在右上角给出了一个总体的分数,随着你采纳它的修改建议,分数会逐渐提高。具体的赋分机制不清楚。
如图 ② 所示,Grammarly 的建议分成了 4 大类:
- Correctness: Improves spelling, grammar, and punctuation.
- Clarity: Helps make your writing easier to understand.
- Engagement: Helps make your writing more interesting and effective.
- Delivery: Helps you make the right impression on your reader.
第一个属于常见的语法纠错,后三类则涉及到改写了(会员功能,暂未体验)。
如 ③ 所示,它提供了抄袭检查的功能。
Grammarly 的一大优点是它可根据具体的应用场景设定目标(比如这里我就很想点击“Academic”,奈何它是会员功能)。
综合来看,对于纯文本(plain text),Grammarly 是个很实用的工具。在实际论文写作中,我一般把它用作语法检查工具,它的涉及到语言风格的改写建议,我采纳的就比较少了。
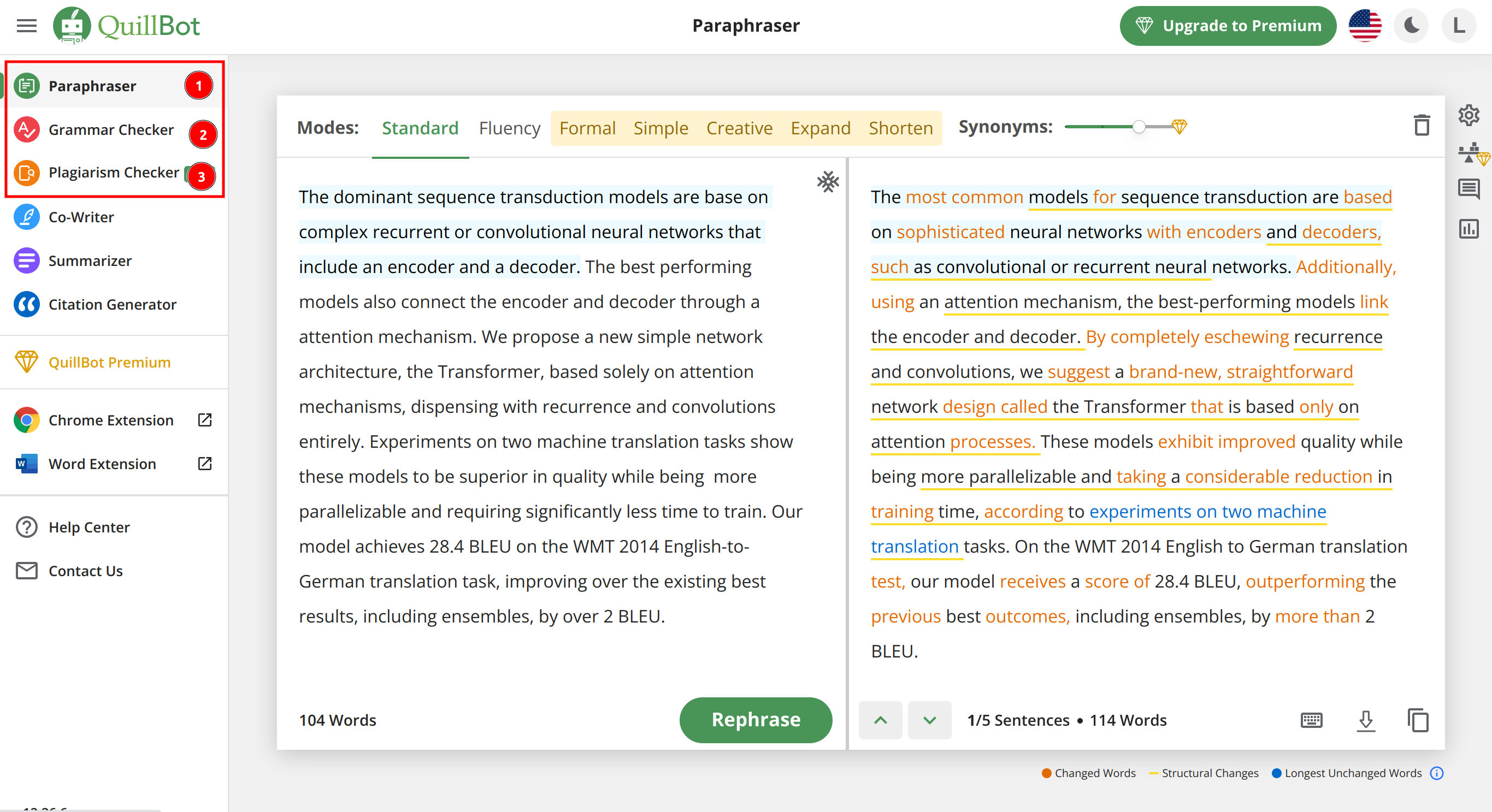
QuillBot
QuillBot 是 Grammarly 的同类产品,和 Grammarly 把各个功能叠在一起不同,它把改写、语法检查等功能给分开了(如下图中 ①②③ 所示)。我个人觉得它提供的改写功能比 Grammarly 更好。
批改网
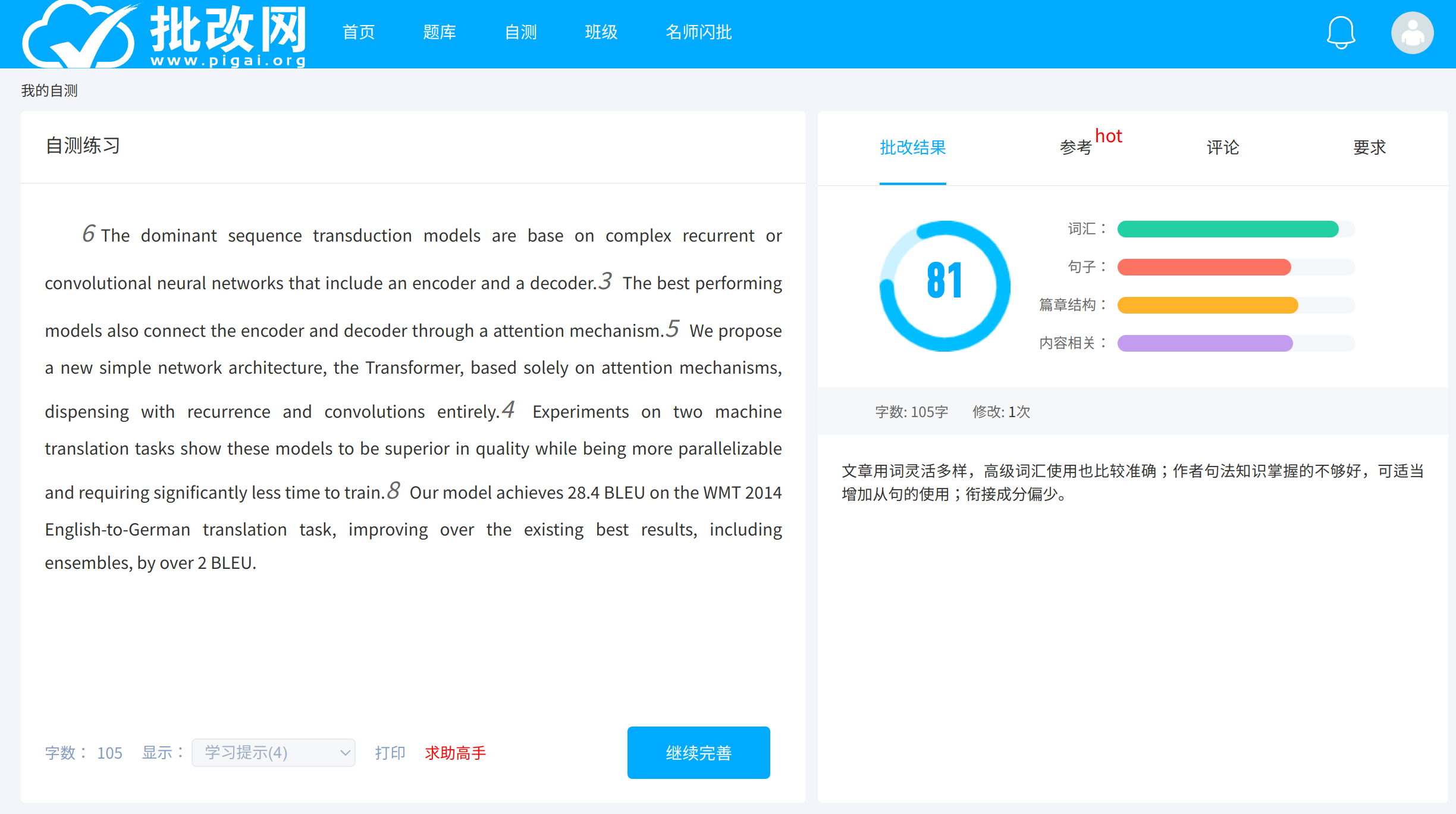
相比之下,批改网的用户体验差得多。它在词汇、句子、篇章结构、内容相关四个方面给出了分数和综合分数。
小结
总结来说,Grammarly 强在拼写、语法检查,QuillBot 强在语言改写,除了这些功能,它们也都提供了抄袭检查的功能。批改网就比较划水一些了。
在技术实现上,它们肯定都用到了经典的基于规则的自然语言处理方法;此外,Grammarly 和 QuillBot 在产品介绍了都强调了“AI-powered”,具体怎么 power 的则就属于它们的商业秘密了(我没做过,不懂🙃)。
开源产品
LanguageTool
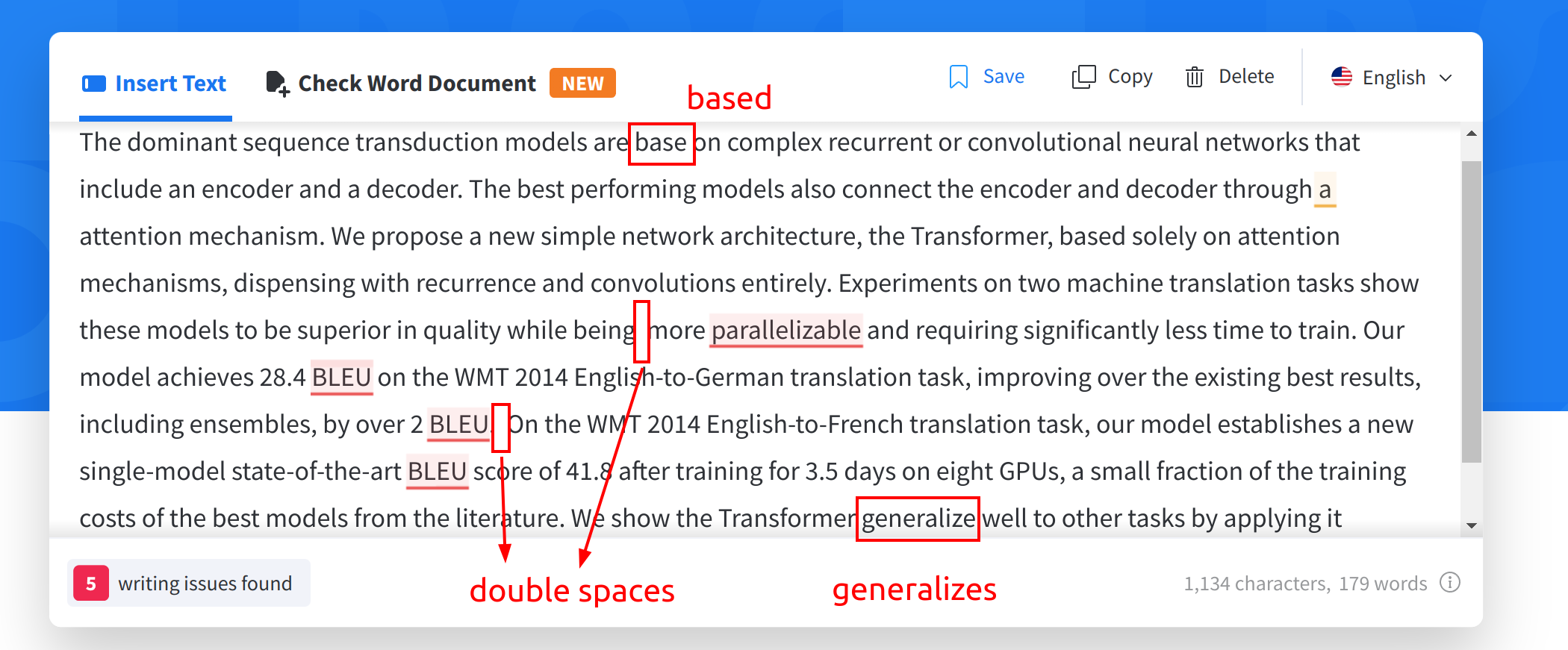
LanguageTool 属于类 Grammarly/QuillBot 工具,是在 GitHub 和 Reddit 搜索的结果中人气最高的。因为其开源所以对我们的自研有很大的参考价值(尽管其 LICENSE 是 LGPL,对二次开发不友好)。
下面是它的试用效果,和 Grammarly/QuillBot 相比,它的语法检查明显要差得多:如下图中所标的 3 类错误它没有发现,Grammarly/QuillBot 则都能正确发现问题。
不过作为开源产品,我们可以从其代码简单了解其基本运行原理。
呃,看不懂 🥲,先跳过吧 :)
nlprule
这个开源产品可以看成是对 LanguageTool 的封装,它不像 LanguageTool 那样火,但是它对我们的参考意义可能更大:
-
它的 LICENSE 是 MIT/Apache,方便做个性化开发。
-
它链接了 LanguageTool 的二进制文件,规避了 LGPL 的“传染”问题。如果我们也要使用 LanguageTool,这是个很好的例子。
-
它提供的接口更加友好,下面是个例子:
from nlprule import Tokenizer, Rules tokenizer = Tokenizer.load("en") rules = Rules.load("en", tokenizer) rules.correct("He wants that you send him an email.") # returns: 'He wants you to send him an email.' for s in rules.suggest("She was not been here since Monday."): print(s.start, s.end, s.replacements, s.source, s.message) # prints: # 4 16 ['was not', 'has not been'] WAS_BEEN.1 Did you mean was not or has not been?
小结
自研英文论文评分系统时,“类 Grammarly/QuillBot”肯定是个绕不开的基础需求,我们可以在 nlprule 的基础上完成拼写、语法检测工作。
不过涉及到语言风格的改写需求时,这些开源产品不太能满足需求:nlprule 中没找到这个功能;LanguageTool 的 Premium 版提供这类功能,但是不清楚这类 Premium 功能是否在其开源的代码中(因为我没细看代码 🙃)。
科研方向
Grammatical Error Diagnosis/Detection/Correction
主要可以分为以下方法:
- 基于规则的方法。这个过程往往涉及到 parse 句子、构造语法树的过程,例如将句子 parse 完后根据规则检查谓语动词的形式是否正确。
- 基于分类的方法。使用一个多分类器预测最佳的替换词。
- 基于机器翻译的方法。常见的双语翻译是将一种语言(“源语言”)翻译成另一种语言(“目标语言”),通过将错误的句子视为“源语言”,正确的句子视为“目标语言”,即可将机器翻译的思路引入到 Grammatical Error Correction。所用的技术方案既有传统的统计机器翻译(Statistical Machine Translation,SMT),又有当前较火的神经机器翻译(Neural Machine Translation,NMT)。
- 基于语言模型的方法。采用无监督方法,不需要平行训练语料。基本思路是把有语病的句子通过修改、替换,找到“最可能”的修正句子。随着大规模预训练语言模型的流行,这类方法越来越受重视。
学术上的方案会比较纯粹,但放在工程上就可能需要混合使用多种方法:
Any robust grammatical error detection system will be a hybrid system, using simple rules for those error types that can be resolved easily and more complex machine learning methods for those that are complex. Such a system may even need to fall back on parsing …
From Automated Grammatical Error Detection for Language Learners
例如,我们可以既使用前面那些开源产品作为基础方法,又使用机器翻译或语言模型方法作为高阶方法。
一些文章:[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21]
以 Grammatical Error Diagnosis 为关键词搜索时,找到的很多文章都是 Chinese Grammatical Error Diagnosis,例如 ACL 2018 有个 workshop 里好多文章都是做的中文语法诊断:https://aclanthology.org/volumes/W18-37/。
Automated Essay Scoring
Automated Essay Scoring,即给学生写的文章打分。托福官方机评工具 e-rater 做的即是这个。这个领域有个很经典的比赛:https://www.kaggle.com/competitions/asap-aes。
这方面的研究大部分做的是给文章整体打分(holistic scoring),小部分研究致力于给出文章在各个维度上的分数。
如果是整体打分的话,这个任务就可以看成是朴素的回归任务:输入为文本序列(纯文本),输出为分数。当然也可以建模成二分类任务,输出越接近 1 越是“好文章”,越接近 0 越是“差文章”。于是,现存的所有用于文本分类的方法几乎都可以用于这个任务:无论是经典方法如 Naïve Bayes、Logistic Regression 还是深度学习一把梭。
不过 AES(Automated Essay Scoring)和普通的文本分类的最大区别可能在于,AES 还会有个 prompt(也就是学生写作文“读题”或“跑题”中的“题”)。于是,用一个 prompt 下的 training set 训练好的模型去预测别的 prompt 的 test set 效果往往就会变差很多。因此,我们尝试利用和改进 AES 领域的方法用于英文学术论文评分时可能需要额外注意下 prompt 的问题。
AES 比较适合我们做学术研究,且我们的研究方法大概率离不开预训练语言模型。不过迁移到学术论文评分时,我们可能会碰到这些难点:
-
哪里获取带有 label 的训练数据。我没有找到公开的定位于学术论文的 AES 数据集。如果我们有往年老师们的批改历史数据,说不定可以用来当训练数据。如果只能自己收集的话:
“好”文章可以选那些被接收的学术论文,至于“差”文章:
- 引入一些非学术性的东西作为“差”文章(比如互联网上一些随机的文章),这样我们的模型才能区分文章是否足够“学术”。
- 引入一些语言很“蹩脚”的东西作为“差”文章(我还没想好来源),这样我们的模型才能区分文章的英语是否“地道”。
以上两点也可以分开,做成两个模型,一个预测是否“学术”,一个预测英语是否“地道”。
-
AES 面对的数据是纯文本,而我们的论文是有很强的结构信息的(这里的结构既包括文字外的图片、表格、公式,也包括文章的 paragraph、section、subsection 这类章节组织),如何考虑论文结构?一个可能的思路是给这些特殊结构赋予一个特殊的 token,如:
[FIGURE]、[EQUATION]、[SECTION—TITLE-START]、[SECTION—TITLE-END]、[SECTION—BODY-START]、[SECTION—BODY-END]……于是,
<section title="Introduction"> Recurrent neural networks <equation src="./equation/02.png"/> </section>变成:
[SECTION—TITLE-START] Introduction [SECTION—TITLE-END] [SECTION—BODY-START] Recurrent neural networks [EQUATION] [SECTION—BODY-END] -
AES 的文本比较短,而我们的文章太长,需要解决计算效率的问题。
一些文章:[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14]
以及 e-rater 的 publications list: https://www.ets.org/erater/publications/。
小结
本节从商业闭源产品、开源产品和科研方向三个角度分析了现有的一些和文本评分有关的方案,应用到我们的英文论文评分系统时:
-
有的方面适合当工程来做:例如基本的错误检测,就适合模仿现有商业产品 Grammarly/QuillBot,直接在开源产品上做二次开发。
-
有的方面适合当学术来做:例如结合深度学习的 Automated Essay Scoring。
有些遗憾的是,我所找的这些现有方案都是面向常规文本的,我还没找到直接面向学术论文评分的方案。
Comments